𝐂𝐡𝐚𝐥𝐥𝐞𝐧𝐠𝐞𝐬 𝐨𝐟 𝐃𝐢𝐬𝐭𝐫𝐢𝐛𝐮𝐭𝐞d 𝐃𝐚𝐭𝐚 𝐒𝐭𝐨𝐫𝐞𝐬


The need for distributed data storage, I.e. replicated data across multiple machines arises to address problems in performance scalability and reliability:
𝐒𝐜𝐚𝐥𝐚𝐛𝐢𝐥𝐢𝐭𝐲: In certain cases, scaling one layer of architecture may not do much more than pass the bottleneck down to a lower level making the database the ultimate load limiting factor.
𝐏𝐞𝐫𝐟𝐨𝐫𝐦𝐚𝐧𝐜𝐞: Geographical distance between users becomes a latency factor unless services are in proximity to their users.
𝐑𝐞𝐥𝐢𝐚𝐛𝐢𝐥𝐢𝐭𝐲: Availability is often achieved by means of replication to ensure that an entity continues to be available even if an instance of it has failed.
Horizontal scaling of databases may allow for increased load handling and address some of the problems above, however, it will create problems of its own, primarily around data consistency as multiple data stores must be kept in sync to maintain data integrity and consistency.
Thankfully, varying forms of caching can aid in addressing the problems of data store replication:
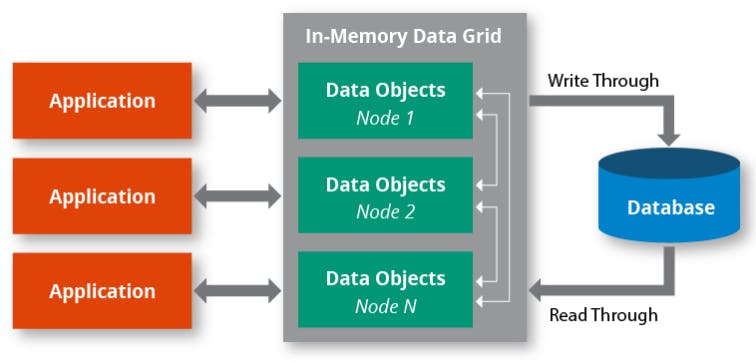
𝐈𝐧-𝐌𝐞𝐦𝐨𝐫𝐲 𝐝𝐚𝐭𝐚 𝐠𝐫𝐢𝐝𝐬 remove the database bottleneck as node (a compute instance such as VM) within a system can have its own local copy of data on the same node as the application and existing data replication engines such as Hazelcast and Oracle Coherence ensures that data remains consistent in between nodes, eventually, data will be written to a database in an asynchronous fashion.
This can be especially useful when multiple nodes rely on the same data set to perform intensive operations as those operations can be performed in isolation of each other and concurrently which is not possible when directly communicating with a database.
Data conflict is potential when dealing with data replication however its impact can be mitigated by utilising conflict resolution through the implementation of consensus algorithms such as Raft and Paxos, one of the key features of Hazelcast is the application of Raft.
A diagram produced by Hazelcast captures in-memory data grids at a high level. Here each node hosting an application will have its own copy of cached data
𝐃𝐢𝐬𝐭𝐫𝐢𝐛𝐮𝐭𝐞𝐝 𝐜𝐚𝐜𝐡𝐢𝐧𝐠: in-memory data grids are suitable when dealing with small amounts of memory (<100 MB) therefore when more memory is required then distributed caches are an alternative, in distributed caching the cache can be stored on a dedicated server which makes data consistency to be less of an issue however it does reduce performance as data access calls are to be performed remotely.
A diagram produced by Hazelcast capturing distributed caching at a high level. Here the cache can be shared by multiple applications and servers

𝐍𝐞𝐚𝐫-𝐜𝐚𝐜𝐡𝐞𝐬: A hybrid caching model that utilises both in-memory data grids and distributed caches to address different scenarios for example in-memory data grids are used for frequently accessed data while a distributed cache is used to ensure availability.
Space-based architecture style leverages in-memory data grids at its core as highlighted by Mark Richards and Neal Ford in their book "Foundations of Software Architecture"
